
Dec 04 2025
Plug SoundHound AI Into Your World With Model Context Protocol (MCP)
MCP support within Amelia 7.3 makes connecting AI agents to your systems easier and faster than ever.
Learn More
Our Company
Named Leader in IDC MarketScape: Conversational AI Platforms 2025 Vendor Assessment
Q: What is agentic voice AI?
A: Agentic voice AI enables users to communicate with an AI agent through a voice channel. It processes and comprehends speech in real time, adapts to interruption, and reasons in parallel to complete users’ requests quickly.
Q: How does it improve on older voice models?
A: SoundHound AI’s Speech-to-Meaning© understands user input and can respond without waiting for a full transcription, unlike older voice models.
Q: What’s the value when callers can interrupt?
A: Unlike the frustrating “sit and listen” experience from legacy voice automations, users can interrupt AI in the middle of a response, creating faster, more natural conversations.
With agentic voice experiences, interactions with AI agents are finally as fast and dynamic as a face-to-face conversation.
SoundHound AI’s Amelia platform now processes and comprehends speech in real time, streaming voice through a single, low-latency model, all while orchestrating highly capable AI agents in the background that get things done for users.
Responses are immediate, adapt to interruption, and reason in parallel to complete users’ requests. Now, you can really talk to AI like it’s any other person, and not be left hanging.
In much of automated customer service, voice interactions still feel like the past. Callers wait through long prompts, listen to rigid menus, and repeat themselves when legacy IVR or older simple voice bots get lost. Every extra second of silence makes it harder to keep customers engaged and contained in self-service.
At the same time, your customers already know what “good” sounds like: a natural, fast back-and-forth with a human who understands interruptions, corrections, and side questions.
Experience agentic voice AI in Amelia 7.3 — real-time conversations with AI agents that move at the pace and dynamics of human dialogue, while unlocking a new level of self-service.
Amelia listens, thinks, and speaks in parallel, so there’s no “wait and listen” feeling. Not only that, but users can jump in and interrupt at any moment, and Amelia adapts without losing context or missing a beat.
This is powered by our Speech-to-Meaning© model, plus rich controls for translation, voices, safety, and a new chat-style UI purpose-built for designing voice journeys. Together, they let you deliver fast, safe, truly conversational voice experiences across your highest-value channels.
Agentic voice in Amelia is about more than fast responses. It’s a seamless combination of hearing, understanding, reasoning, and acting that behaves much closer to a skilled human. Amelia can:
This combination is ideal for CX and contact center leaders who need modern voice journeys that are just as capable as any mobile application or AI program.
Plus, the new agentic voice capability operates as a voice channel on top of Amelia’s existing agentic AI core. The same conversation flows, tools, and LLM integrations you use for chat or traditional voice now power real-time, streaming conversations across telephony, web, and in-app experiences.
Behind the scenes, platform-level resilience and observability improvements help keep these real-time journeys stable and debuggable as adoption grows.
In traditional systems, barge-in — which allows users to interrupt AI in the middle of a response — is either unsupported or fragile. Callers have learned not to talk until the automated system is done reading its script, because talking early usually leads to confusion or an error.
Now, there’s no more waiting for AI to finish its thought. With our new barge-in capability for voice, users can jump in the moment they’re ready. In fact, it’s encouraged. Amelia will pause, listen, and move to the next part of the conversation without missing a beat or losing context.
The result: faster, more natural conversations without the frustrating “sit and listen” experience from legacy voice automations.
Most voice experiences still rely on a strict turn-taking model: the system talks, stops, records, processes, and then finally replies. That pattern introduces frustrating latency, “dead air,” and frequent misunderstanding — especially when customers try to move faster than the system can handle.
For high-volume customer service environments, those limitations show up as:
Agentic-enabled voice AI removes these pain points by giving callers a responsive, interruptible, and branded experience that feels as fast as a face-to-face conversation.
Instead of treating speech recognition, language understanding, reasoning, and text-to-speech as disconnected stages, we bring them together into one tightly integrated flow.
SoundHound AI’s Speech-to-Meaning© approach continuously processes incoming audio, interprets intent, and plans the next step of the conversation. There’s no need to wait for a full transcription before understanding or acting.
For your teams, that means:
With the new streaming architecture, Amelia can think and speak at the same time. As soon as enough meaning is captured, Amelia begins to generate and stream response audio — even while back-end orchestration and reasoning continue.
This enables:
Amelia now speaks over 40 languages natively and can even speak them within the same conversation. Users can start a conversation in English, switch to Spanish, and then practice their French — all in the same breath. Amelia will detect the language without being prompted and speak it back in real time.
And, no matter where your users are in the world, Amelia can understand. With additional customization, Amelia will learn any language you need.

Voice is one of the most powerful parts of your brand experience. With Amelia 7.3 you gain significantly more flexibility in how Amelia sounds across user journeys.
Through integration with OpenAI TTS voices you can:
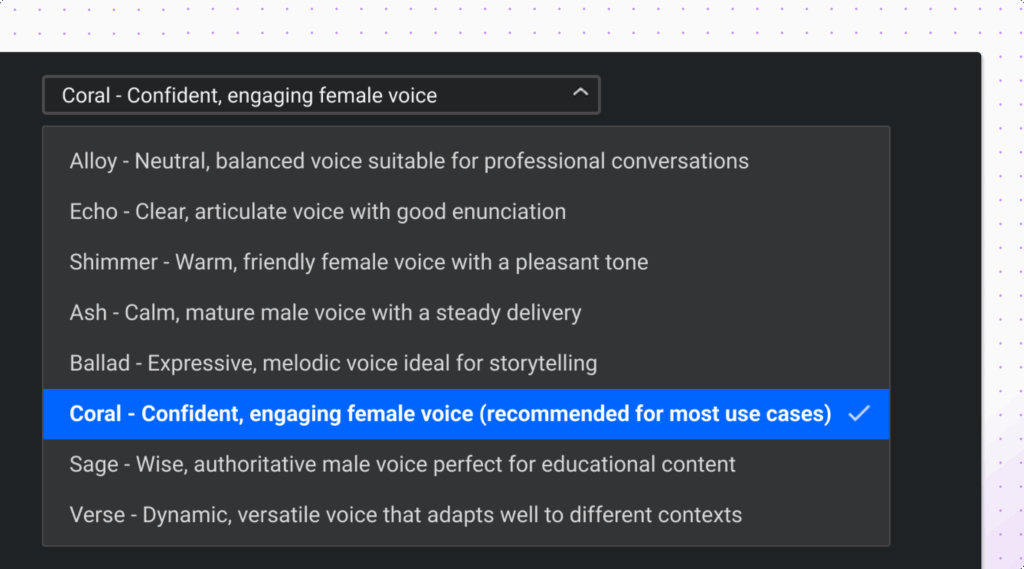
These text-to-voice features are managed via Admin UI controls, where teams can enable TTS, choose voices, and configure how they are applied to specific flows. Amelia 7.3 also includes a chat-style UI specifically optimized for building and testing real-time voice.
With this UI, designers and developers can:
This speeds up time-to-value and makes it easier for multi-disciplinary teams — CX leaders, conversation designers, and architects — to collaborate on voice journeys without needing specialized tools.
Agentic voice at human speed is a key step in Amelia’s broader vision: a platform where reasoning, orchestration, and voice interact seamlessly across channels.
It reinforces three pillars of the Amelia platform:
As you evolve beyond traditional IVR or voice automation, Amelia gives you a single agentic platform that can handle both today’s high-volume calls and tomorrow’s more complex, multi-modal journeys.

Jack Gantt is the Director of Product Marketing at SoundHound AI, where he focuses on the Amelia 7 and Autonomics 3 platforms to bring accessible AI agents to market. With a deep background in GTM and technology strategy, Jack previously served as a Senior Consultant at Boston Consulting Group (BCG), building end-to-end growth engines for new ventures. He specializes in bridging the gap between complex AI technology and market adoption.
Subscribe today to stay informed and get regular updates from SoundHound AI.

