“The idea is that we want to create a platform that allows collaboration between developers and is not centralized. It allows people from all different backgrounds, companies, and expertise to contribute to the platform,” says SoundHound’s VP of Engineering, Joe Aung on Collective AI®.
Recently, SoundHound’s Director of Product Marketing, Arvind Rangarajan, sat down with SoundHound’s Co-Founder, CSO, and SVP of Engineering, Majid Emami, VP of Engineering, Joe Aung, and Senior Director of Product Engineering, Chris Schindler, to discuss how SoundHound’s proprietary technologies, including Speech-to-Meaning®, Deep Meaning Understanding®, and Context Aware™ are processing speech more like the human brain than any other voice AI technology available.
During the webinar, they explored SoundHound’s different approach to conversational AI, branded voice assistants, content domains, predictions for the future of voice AI, Active Arbitration, and more.
Watch the entire webinar here or read the recap with answers to additional questions that were submitted for the Q&A.
Q: When you and other founders first conceived of a voice AI platform, you set out to create technology that mimics the way humans communicate with each other. Can you explain that concept a little bit and how it’s different from how other companies approach this technology?
Joe: So traditional speech recognition engines have 3 main models that they utilize. There are acoustic models that help you map the audio features to the phonetic features. There are language models that help you predict the probability of different sequences of words. Then, there are these pronunciation models that help you predict the words in the different phonetic ways they’re pronounced.
At SoundHound, what we’ve done is incorporated the NLU (Natural Language Understanding) into the system as well. We have models and domains, and then these things also play a role in speech recognition as well. What this does is it gives you the benefit of adding the structure and data from hundreds of domains that people create and brings that into the speech recognition engine so we can make better decoding decisions.
It also allows the NLU to run in real-time with speech recognition. Then, you see that the perceived latency of that system is actually zero, which makes it really snappy and fast, very similar to how the human brain works.
Q: In addition to a different approach to technology, we often talk about the difference between a custom branded voice assistant that you can build with us versus adopting a big tech solution, such as platforms like Google or Alexa. Do you have a perspective on that?
Chris: As Steve Jobs said, “It’s imperative to start with a customer and work backward.” I’m paraphrasing, but for that principle, it’s that people should talk with voice AI as if it were another person, which means they’re having a personal conversation with your company. That’s what they’ll remember.
As a result, you need to have control of that conversation since it is representing your brand and you need a strong partnership with voice AI experts to help craft the best experience. When evaluating a partner, long-term success is based on aligned incentives. Some key examples include:
- You have full access to all the voice AI features and techniques
- The menu of topics available empowers your designers to craft the right experience
- Your solution platform doesn’t have other motivations for how to use customers’ private and secure information
- The skills in your design and engineering shops fit naturally within the solutions tools
Q: How does that perspective inform our product roadmap?
Majid: We build our platform to be a general platform, but at the same time, it’s built in such a way that it can be customizable. We want to be able to provide solutions for customers that satisfy their needs. We allow this customization without sacrificing the generality of the solution. The customization allows us to look at business verticals where our solution can provide the highest level of impact.
At the end of the day, we are a technology company where we are solving a problem that people deal with in their day-to-day lives. We provide solutions that we can quickly customize for that particular vertical.
Q: Can you address the many ways a voice assistant can be customized and the importance of customizations for a branded experience?
Joe: There’s functionality, and then there’s personality. You have to recognize that voice assistants have different applications to focus on different tasks. If you have a voice interface for your television, it doesn’t need to know how to roll down the windows in a car. Or, if you have a voice interface for a music app, it should prioritize search results for songs and artists.
At SoundHound, our conversational AI capabilities are organized into domains, such as music, movies, or navigation. Based on what your voice assistant is trying to solve, you can pick which functionality you want. You can pick and choose from a menu of different domains. In addition, we have custom domains where you can build your own domains and personalize them with your experience, data, and dialogue flows.
On the personality side, you can choose a name for your voice assistant. You can choose the voice and customize the voice in the future. You can even customize responses, such as small talk and chit-chat, so that they can reflect what you want in your brand.
Q: Connectivity options are taking on a larger role in determining what types of devices can be voice-enabled versus when voice assistants were solely dependent on the cloud. Can you talk about some of the opportunities that are opening up and how you see Edge connectivity playing a part in the evolution of voice AI?
Majid: Edge connectivity is providing an opportunity for us to reduce latency and increase privacy. Our devices these days have a lot of power, and we can do recognition on the device with a high degree of accuracy so that when you are in a car driving around and don’t have access to the network, you can still complete many tasks without having access to the cloud. It improves privacy, so users don’t have to share data with the cloud if they wish to opt out.
Q: How does this impact a company’s decision to have a branded voice assistant versus using a big tech solution?
Chris: First, Edge connectivity shouldn’t mean degraded experiences or a loss of the customer experience. That needs to remain consistent. At the same time, it’s also necessary to plan for cases where the cloud isn’t connected to ensure that customers have a clear and consistent experience.
Also, customers want to interact with a device that best empowers them. They want to interact with something that makes it simple and easy. That means as devices become more pervasive and available in homes and cars, the crucial opportunity becomes negotiating across devices and services.
Finally, privacy, security, and speed of response are very important to customers and affect buying decisions. As companies consider their product offerings, Edge connectivity may resonate strongly with certain customer segments who value privacy and conversational ease.
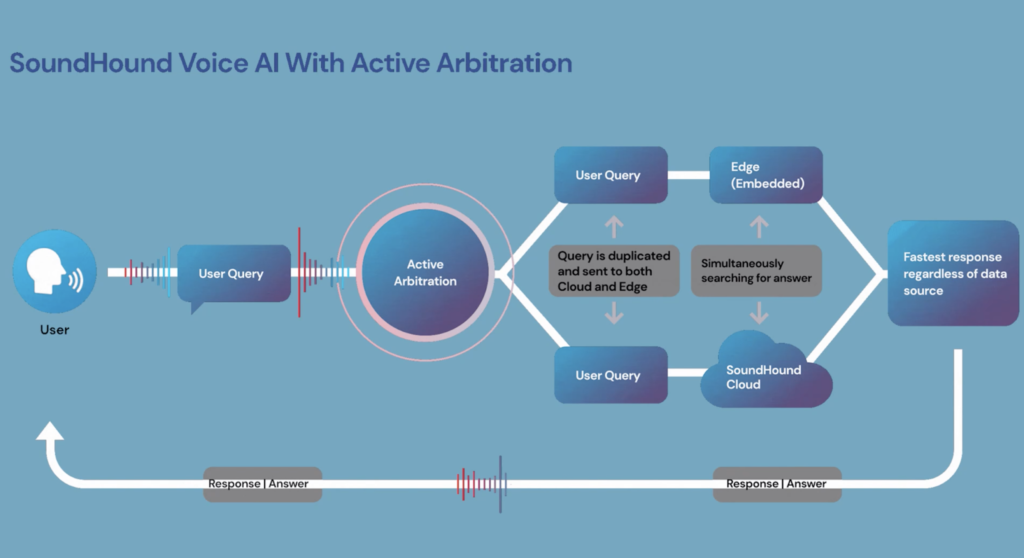
Q: Can you walk us through Active Arbitration and explain how that impacts the user experience?
Joe: In the Cloud, we have virtually infinite computational power, but it requires a strong internet connection on the device. The computation is much more limited, but the device is always available. Our Edge+Cloud systems do this arbitration to get the best of both worlds. If you have a strong internet connection available, you can leverage the most computational power and get the most accurate speech recognition capabilities for your voice assistant.
If you lose connection, your system will gracefully fall back to the on-device capabilities. It still gives users important features, like controlling the devices in the car, making phone calls, or controlling audio, but it should all be seamless and communicate to the user gracefully what it’s capable of at the appropriate time.
Q: I wanted to dive a little deeper into user experiences and talk about the ability to provide accurate answers that bridge more than one content domain, such as navigation and Yelp, for example. Can you explain how that works?
Joe: Building domains is challenging. There’s a lot of work involved, and the number of domains that people want to build is very numerous, countless even. Collective AI® is SoundHound’s approach to the scalability of building these domains of conversational AI and general conversational development.
The idea is that we want to create a platform that allows collaboration between developers and is not centralized. It allows people from all different backgrounds, companies, and expertise to contribute to the platform. For example, for a navigation query and a restaurant search with Yelp, this allows two developers, one that’s building the navigation domain and one that’s building the Yelp domain, to share the capabilities and collaborate.
They can share things, like data, dialogue patterns, and entity models, in a way that allows each others’ domains to enhance each other and build on top of each other. The idea is that as we add more of these domains to our platform, the barrier to creating a new domain becomes less and less. A lot of the building blocks are already there. You can already share them, and you can enhance the existing building blocks.
Q: What’s happening at the technology level to differentiate solutions that are truly conversational from those that are less sophisticated?
Joe: It’s hard. Human conversation is very complex and multifaceted. As a technology, you try to break things down into sub-problems and solve those. When you look at human conversations, there are so many different aspects that you have to deal with. There’s eye contact and gestures that both play important roles. There’s also a mutual understanding between two people who are speaking to each other that forms the basis of communication.
When we talk to each other, we don’t restrict ourselves to a finite number of intents or a small set of parameters. We’re not constrained to a fixed turn-taking paradigm. These more sophisticated solutions need to be able to allow natural behaviors. We need to allow users to interrupt the system or use subtle or complex language. Voice assistants need to be able to understand cross-domain queries or compound queries. At SoundHound, we have a lot of different pieces that need to come together to simulate a lot of the really natural conversational experiences that we’re used to when talking to each other.
Q: How do you see this playing out in the market?
Chris: There are several ways. I’m going to approach this from a customer perspective. First, voice-capable experiences are going to require several evolutions to achieve what Majid and Joe have been talking about. They must actively learn from customers.
Many products today teach customers how to use a voice assistant by effectively not responding in some cases. Customers are willing to put up with the pain of trial and error to a point. For conversational AI to be successful, this model has to be flipped. Voice assistants must learn from people.
Second, voice assistants must develop for each customer. They need to understand and handle interruptions and know when it’s appropriate to be verbose and wordy or succinct and direct. They need to listen more carefully to a person’s tone, vocabulary, and conversational rhythm to better understand what customers mean and are seeking. SoundHound provides a number of those pieces for the framework. Experiences that naturally communicate with a customer are ones that will win hearts and minds.
Q: If we all had a crystal ball, how would we see conversational intelligence evolving in the next five years?
Majid: Predicting the future is hard, but I really believe we have all of the right ingredients to build a technology that humans prefer to interact with for most of their day-to-day tasks, such as placing an order or booking an appointment, as opposed to talking to a human.
Chris: One of the things I see is that we have to develop emotional intelligence so that our voice assistants are more socially adept. As voice AI becomes more pervasive, we’re interacting with a broader group of people. The ability to listen to verbal and nonverbal communication and understand social rules is going to be paramount.
For a voice assistant to say, “I’m sorry. I know you’re having a difficult experience right now,” requires building great tools and guidance to educate and empower designers. This is a whole new paradigm. Ultimately, we have to teach voice Ai to be great collaborators.
Joe: My take on this is a slightly different angle. I’m not going to talk about capabilities but instead the accessibility of voice technology.
I’d like to think that you’re going to see the availability of voice AI expand to new markets and segments. In the past, when you build voice experience, they were expensive and mainly restricted to assisting people that were very highly compensated in jobs like doctors, lawyers, and investment professionals.
I think soon you’ll see voice AI assist other types of jobs, such as people on retail shop floors, fast food drive-thrus, construction sites, or waiters. Even jobs where compensation isn’t very high will soon have accessibility to use voice AI to make their jobs more efficient.
On the other side, I think the ability to build voice AI in the past had a very high technical bar. You’d have to have highly trained scientists and engineers to build these voice AI experiences. In the future, I think you’ll see the tools to build these experiences and allow people like product designers, storytellers, advertising agencies, or even children and kids in school to build voice AI experiences.
I think, soon, everybody will be able to build conversation AI, and this should unleash an incredible amount of creativity in the industry and bring new voice products to the market that we haven’t even imagined.
Questions from the audience
Q: How do you guarantee the performance of an AI system for your customers?
Chris: When we’re dealing with voice AI, it’s a really fascinating opportunity in that a customer can literally say anything. When we’re considering this question of guaranteeing performance, I find that it boils down to measuring the customer expectation and what’s possible.
There are a deep set of metrics involved in that, but I think at the top of the line is examining what did the customer expect when doing this and how effective was the voice AI in responding to that? Then you need to iteratively and continuously make improvements to the customer experience that customers notice.
Q: How do you solve the problem of other languages in speech recognition?
Majid: That’s a good question, and SoundHound does support these languages now. One of the issues that needs to be solved for each language is data. We get access to data. Then we train our models. Finally, it’s a live system, so we have the initial version that we launch, then we do measurements in the field and collect information to improve on that.
Q: How does SoundHound deal with pronouns and references to previously understood semantic notions?
Joe: When you’re talking about conversations, we have conversational context for things like pronouns and references to entities.
In the conversational context, they could refer to people, places, or entities like dates or times. SoundHound will naturally handle these and track the conversational context in a structured way. When the customer issues a query later on and uses things like pronouns and references, we can look back in the conversational context and pick out the most relevant entities.
Q: Does SoundHound do NLG as part of your solution?
Joe: NLG is really interesting, and it’s an active area of research with two different approaches to it. First of all, at some level, for many products, you want to have control over the NLG. For people who are building their products, the response that goes back to the user is a big part of the company’s branding and a big part of how they want to represent themselves. From that point of view, you want to have pretty tight control over it. You don’t want to just generate random things and risk tarnishing a brand in an unintended way.
At the same time, you have to realize there are certain aspects of NLG that should seem more natural. There should be humor, personality, and randomness. It shouldn’t be completely scripted. There should be a little bit of variability in it to mimic natural behavior. At SoundHound, we strike a balance of giving our customers control over exactly what the functionality is while also giving them a little bit of that randomness and serendipity to the responses.
Additional submitted questions
Q: Do you provide tools to build custom language models for different domains?
Joe: SoundHound’s Speech-to-Meaning® technology allows domains to contribute to the language model. Activating domains will directly increase the probability of relevant sequences of words.
Majid: We allow the uploading of some type of data, like contacts, dynamically. We are also working on tools that will allow developers to upload any type of grammar and entities dynamically. This tool is available in its alpha stage for testing based on demand.
Q: Do you guys have thoughts on how your tech can be used in “the workplace”? How can Conversational AI help people do their jobs better?
Joe: There are so many areas where conversational AI will help workers. For example, we can help retail shop floor workers more easily access product information like location and availability. We can help construction workers take notes and make updates without having to take off their work gloves. We can help call center employees find relevant information faster.
Q: Do your domains include both NLU and capability/goal/intent fulfillment for the recognized requests for those capabilities?
Joe: Yes. Domains include NLU, Dialog Patterns, Entity models, intent and slot models, personalization features, data and APIs for the fulfillment, and natural language generation.
Q: Can I adjust all the language, phonetic and semantic models based on customer-specific or domain-specific data (e.g. proper names) in real-time?
Joe: Absolutely. As an example, our restaurant technology allows you to upload the menu to our system, and we automatically support new item names, categories, and modifiers.
Want to dive into more webinars? Check these out:
At SoundHound, we have all the tools and expertise needed to create custom voice assistants and a consistent brand voice. Explore SoundHound’s independent voice AI platform at SoundHound.com and register for a free account here. Want to learn more? Talk to us about how we can help bring your voice strategy to life.